Introducing Speech and Language Processing
John Coleman
Cambridge University Press, 2005.
£23,99, 314 p., ISBN-13: 9780521530699.
Reviewed by Graham Ranger
Coleman's Introducing Speech and Language Processing (henceforth ISLP) is a very well presented manual running to more than 300 pages which aims at initiating the reader in some of the fairly complex and technical computational and mathematical methods used in processing linguistic sounds and structures. An introduction is followed by eight evenly balanced chapters each of which targets a particular technique in speech and language processing. Each chapter is headed by a page featuring a "chapter preview" and by a list of "key terms" to be found in the chapter. ISLP contains a good number of exercises both within the text of each chapter, to be done while reading. At the end of the chapters there are further exercises, advice for complementary reading and preparatory reading for the next unit. The index is perhaps a little sparse but it is usefully complemented by a glossary of technical terms. In addition to the book itself, the accompanying CD-ROM contains a good deal of extra material including software (a C-code compiler, a Prolog interpreter, a text editor and a sound editor) in addition to accompanying examples and data files. A companion website http://www.islp.org.uk/ provides answers to some, if not all, of the exercises, help with bugs and problems installing or running the software, free extras, updates and links to other relevant websites. Very little has been left to chance in ensuring that the reader benefits fully from his or her reading of ISLP!
I will begin by presenting the goals of ISLP as they appear in Chapter 1 as well as my own particular interest in these goals before going on to look at the main body of the book.
ISLP is, Chapter 1 tells us, "a first, basic, elementary and short textbook in speech and natural language processing for beginners with little or no previous experience of computer programming […] it is primarily written for language, speech and linguistics students. Consequently, I shall assume some prior knowledge of basic linguistics" [2]. I ought perhaps to say that I am not an expert in computing but a lecturer in linguistics and so this review is written from the point of view of the target student rather than from that of the lecturer interested in adopting ISLP as a coursebook. One of the purposes of ISLP, Coleman tells us, is to bring together two fields in language processing which have traditional remained divided: "signal processing […] which [is] normally taught in electronic engineering degrees, and computational linguistics, which is mainly directed to students of computer science or linguistics" [3]. Coleman goes on to provide a number of reasons to use ISLP, for students in various fields of research. His own reason for writing the book, he tells us, "rests on a refusal to let the old sociological divide between arts and sciences stands in the way of a new wave of spoken language researchers with a foot in both camps" [4]. The book adopts a hands-on approach to programming skills. "The emphasis […] is on pratical exercises in the use and modification of computer programs written in C and Prolog, in order that students will rapidly gain confidence and acquire new skills" [5]. The necessary C and Prolog programs are included on the CD-ROM, as I have said, and the reader is encouraged to "tinker" with these, the better to understand how they work. The introduction goes on to indicate the basic "computational set-up needed" for the book and the "computational skills" that the reader must have. This paragraph, I would suggest, is a little disingenuous, beginning as it does: "You need to know a little about how to use a PC: 1. How to power it up (and, if necessary, how to start Windows). 2. How to use the mouse and keyboard." Some of the skills required later on in the manual, in particular concerning the installation and use of the C compiler and the Prolog interpreter definitely require a little more expertise than this, in particular when things do not go as expected! The introduction ends with the structure of the book, which follows two "'strands' […] one on speech processing and the other on natural language processing" [10]. I will be following this in the next paragraphs, dealing firstly with chapters 2-4 (speech processing) then with 5-9 (natural language processing) both in terms of speech recognition (6-7) and grammars (8-9).
Chapters 2-4 look at speech processing and provide an introduction to working with C programming. Chapter 2, "Sounds and numbers," is conceived around a confidence-building exercise first generating and then interpreting a cosine wave in terms of sound. To produce a cosine wave we cannot take literally every point on the wave, and so we must decide to take a limited number of samples at regular intervals.
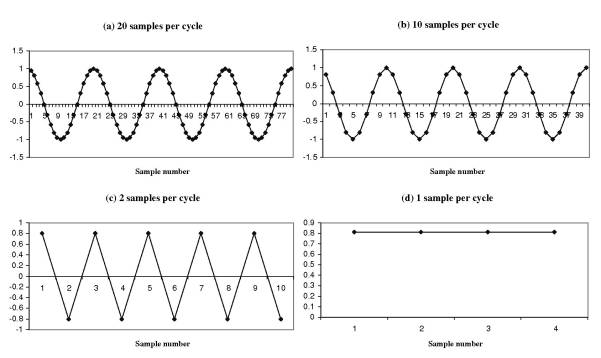
Figure 2.6: Accuracy of representation of a signal at different sample rates, relative to the frequency. [28]1
These samples are measured using a discrete series of values at fixed intervals. This transformation of the continuous to the discrete is called quantization (2.4). The passage in the opposite direction involved when a signal is played back, for example, is called reconstruction. A series of 64000 quantization values (±32000) is enough, Coleman tells us, for "quite a high fidelity representation of speech" [26]. 64000 values can be encoded using 16 bits (or binary digits): one denotes the sign (+ or -) while the other 15 give us 215 (or 32000) different levels. (At this point in the chapter there is a short paragraph representing an exchange in a lesson perhaps, between the student and the lecturer featuring the student's question "What is the definition of a bit?" and the answer. I enjoyed this original feature of ISLP, in particular since the naive questions of the typical student frequently corresponded to questions I was asking myself while reading. I did however find, in some chapters, when the going got tough, that the student fell conspicuously silent!). Next, the chapter comments in detail upon the listing of a program file called coswave.c the purpose of which is to produce a cosine wave by using the parameters introduced earlier in the chapter (the samples and the values assigned to them). The chapter closes with a summary and a number of exercises to compile and run the coswave.c program. Compilation involves turning the C code of the program firstly into an object code which the computer can understand (the file is then called coswave.o where the suffix .o denotes object code) and then into an executable program bleep.exe (the name bleep is arbitrary). This can now be run. It writes to the disk a data file coswave.dat which can be imported into a sound editor like "Cool Edit" (the program provided on the CD-ROM). These operations are done by typing out commands on the command line, not something many of us are used to doing, I imagine. The next exercises involve modifying the parameters of coswave.c (samples and values) to produce differences in the sound produced and even getting the program to write out the sample numbers and values into a text file which can be visualised or converted into graphic form using Excel or similar software.
Chapter 3 "Digital filters and resonators" looks at how one can filter out certain elements of sound according to one's needs. Coleman begins by presenting the Root Square Mean as a way of obtaining the average amplitude (or loudness) of a sound and he gives a commented C program which does just that and invites us to try it out on a spoken sound file joe.dat on the CD-ROM. From this he goes on to look at how to calculate not the overall mean but the running mean. This will give us a series of mean values calculated by average out a window of sample values. So if we are dealing with samples 1-10, and we base our average mean on four consecutive samples at a time, the first will correspond to the sum of 1-4 divided by 4, the second to the sum of 2-5 divided by four, the third to the sum of 3-6 divided by 4 and so on. The point of this, as Coleman describes, is that the "grosser, more slowly changing aspects of the input won't be affected by the averaging; whereas very fast local changes in the input signal (inside the four-sample moving average) are affected by the averaging operation" [52]. This can be useful for removing tape-hiss, for instance. Another commented C program gives us a way of doing this. The next step is to widen the window to 100 samples, then, to avoid using too much processing energy, to provide a method for calculating the average of these 100 samples by using previously calculated values, producing a recursive, or Infinite Impulse Response (IIR) filter. A combination of high pass and low pass filters can then filter out unwanted very high or very low frequencies, leaving only a certain band-width (the resulting combined filter is called a band pass filter). A further C program does this. The chapter concludes by looking briefly at the Klatt formant synthesizer. Here, as I understand it, the filter works the other way round, by producing target band-widths which can be combined to reproduce a representation of speech. The presentation here is fairly technical and too quick, I feel, to be fully understood. Coleman does, however, provide further references for the interested reader.
Chapter 4 is the last chapter of the first "strand" in the book—speech processing—and, I found, the most technically demanding of the whole book. Chapter 3 had ended by looking at how different band-widths can be combined to synthesize speech. Chapter 4 begins by showing how we go about extracting this distinctive combination of band-widths—the spectrum—from a given portion of speech. This is done using the Fast Fourier Transform algorithm. Coleman includes a C program for making a spectral analysis of a portion of speech. The resulting spectrum can be plotted on a graph via Excel and this can in turn be compared with the results given by the sophisticated sound editor Cool Edit (also included on the CD-ROM). A second operation (with its accompanying C program) allows us to separate harmonic peaks from resonant peaks, given us the cepstrum. The next topic dealt with in the chapter is pitch-tracking: two methods are given to enable us to sort out voiced sounds from unvoiced sounds. Each method has its C program and these are commented upon and explained. The last part of the chapter presents the method of linear predictive coding (LPC). As I understand it, the idea of LPC is that, rather than storing actual values for each sound, the program stores predicted values and error values relative to these predictions. This is shown to be more economical, in terms of processing cost, and is apparently an important technique in mobile phone technology. I must confess that I felt very much out of my depth in this chapter. On several occasions the author warns us that the mathematics involved is too complex for the course. This caveat inevitably makes the analyses excessively allusive, which is rather unsettling for the non specialist reader.
Chapter 5 is a pivotal chapter between the speech processing and language processing strands of the book. In it the author presents the theory and practice of finite-state machines (FSM's). "A finite-state machine works rather like a board game in which you move a piece from one position to the next in order to get from one side of the board (the start) to the other (the end)" [112]. A finite-state machine allowing us to generate English-like monosyllables is represented graphically with the following diagram:
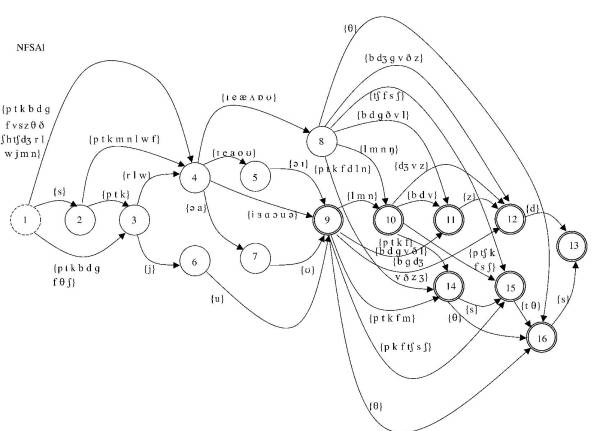
Figure 5.3 NFSA1: a finite-state model of English-like monosyllables. [114]
Starting from state 1 we move through the machine step by step until we reach an end state. This finite-state machine is implemented using the Prolog programming language (rather than C). Coleman comments upon some of the more significant differences between the two languages and then on the program itself. There follows an exercise in which the reader is asked to try it out using the SWI-Prolog interpreter which can be installed from the CD-ROM. The next step is to move to finite-state transducers (of FST's). These are like FSM's except that they work with pairs of symbols. Again a Prolog implementation of this is provided, with the aim of relating English-like phoneme strings to spellings. And so the Prolog query
?- accept ("squeak",_). yields the output squeak skwik i.e. the grapheme string / phoneme string pairing. Inversely, the query ?- accept(X,"f0ks").
allows us to generate in turn a series of outputs focks, fox, phocks, phox, all potential grapheme strings corresponding to the phoneme string input. And so we can map from graphemes to phonemes or phonemes to graphemes indifferently. The next step is to relate speech to phonemes by pairing off phoneme symbols with LPC vectors for the corresponding sounds. From there we can in theory take speech as input and label it phonemically as output. If the machine is working on a series of samples taken at very short intervals then it has to be able to reduce them to one symbol. In the word father for example, the machine might, according to how many samples it has, return /AAAAADDD/ which would then be reduced to /AD/. This is fine, but what happens if, in the middle of the /A/ there is a sound which the machine identifies to a /V/? To deal with such glitches, a probabilistic element has to be integrated into the machine. Two further applications of FSM's are given, the first in application of phonological rules for trisyllabic shortening and the second to provide a simple grammar. The chapter ends by considering a number of objections to FSM's first formulated by Chomsky in Syntactic Structures.2 This is done effectively in the form of a student-teacher exchange.
In Chapter 6, Introduction to Speech recognition techniques, Coleman divides such techniques into two sorts: knowledge-based approaches and pattern-matching approaches. The first relies on linguistic theory, the second on database examples. He looks at knowledge-based approaches first presenting the decision tree as a way of recognising speech. An example of a decision tree for phoneme recognition is given below:
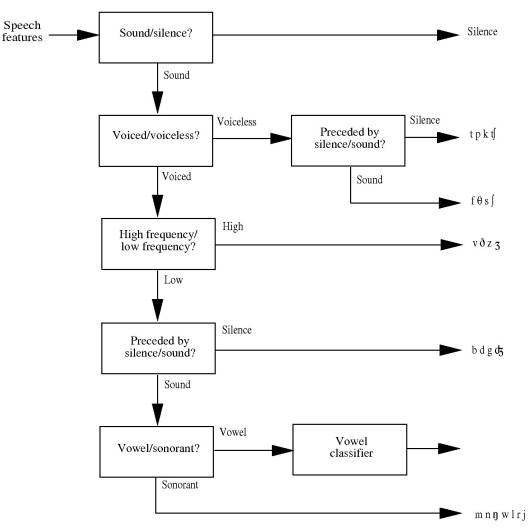
Figure 6.3: A decision tree for phoneme identification (after Rabiner and Juang 1993:48). [160]
Such methods are apparently not always reliable and hence are less favoured in commercial applications. Coleman looks briefly at ways in which such systems can be made more flexible and less inclined to fail in case of error. The chapter then move on to Pattern-matching approaches to speech-recognition. Here, rather than look for minimal features, speech samples are compared with a database of recorded patterns, often consisting of whole words. This very pragmatic approach to the problem has not always interested linguists but has achieved more significant results and receives commercial applications. One of the problems it presents, however, is that the sample is not necessarily temporally aligned with the database example. This requires us to implement something called dynamic time warping: a method for stretching or compressing samples intelligently in order to align and compare them with recorded examples. The method of dynamic time warping is explained in some detail. The chapter ends wth a consideration of problems posed for the pattern-matching approach by further sorts of variation: accent, gender, speaker, etc.
Chapter 7 returns to the probabilistic finite-state models evoked towards the end of Chapter 5. Probabilistic methods, Coleman tells us, are useful in situations of uncertainty whether these be acoustic (as addressed with dynamic time warping in Chapter 6), categorial, structural or homophonous. Uncertainties may, moreover, accumulate within a single unit of speech. The question of structural uncertainty is addressed by appealing to the preceding context. Hence in the sequence the low swinging he considers that the possibility of swinging being an adjective is 0.8 while that of it being a noun is 0.2 on a scale of 0-1. A reference corpus is used to establish probabilities. A problem arises though, since one may produce a perfectly good sentence which would receive a probability estimate of 0 simple because it does not occur as such in the reference corpus. This problem is answered in the following way: rather than take into account the whole sentence, the probability of a sentence occurring is calculated, following the Markov assumption, as the product of the probability of bits of the sentence only. For example the probability of finding I saw a Tibetan lama in a corpus may be calculated using bigrams (sets of two words) as the probability of finding "I" times the probability of find "I saw" times the probability of finding "saw a" and so on. Coleman considers a number of problems such probabilistic models (known as Hidden Markov Models) have to take into account. This part of the chapter was, I found, rather too technical and soon became difficult to follow for the non specialist. The chapter ends with a consideration of Chomsky's objections (in Chomsky 1957, 1965 and Miller and Chomsky 19633) to statistical models of language (including Markov models) and a number of possible rejoinders to Chomsky's criticism.
Chapter 8 Parsing brought me back to more familiar territory with a Prolog implementation of phrase structure rules of the form S à NP + VP; NP à det + N etc. Coleman first asks the reader to parse a given sentence intuitively and then looks at how a program might go about the same task. Whereas a person intuitively adopts a bottom-up approach (i.e. starts with the words and then works from them towards abstractions such as NP, VP or S) a program has to take a top-down approach, beginning with the highest term (S or IP) and working down, asking itself "how can we build the tree downwards so as to generate the input string?" [225]. A simple parsing program ("a 'toy' grammar” 232), written in Prolog, is worked through, and we are told how the computer has, whenever it reaches a dead-end, to backtrack and try another route. This program, called dog_grammar.pl, will, when given a string of words, tells us whether a string is well-formed or not, using recursive descent parsing. The Prolog query ip([the,quick,brown,fox,jumped,over,the,lazy,dogs],[]). returns the answer: Yes. It can also generate a list of all possible sentences, corresponding to the lexicon and the rules programmed into it. More usefully, perhaps, a second program works as a simple parser, so that the query
ip(Tree, [the,quick,brown,fox,jumped,over,the,lazy,dogs],[]). returns the answer:
Tree = ip(np(det(the), adj(quick), adj(brown), n(fox)), vp(v(jumped), pp(p(over), np(det(the), adj(lazy), n(dogs)))))
We turn from sentence structure to syllable structure and another Prolog program syllable_grammar.pl does a similar job to the above dog_grammar.pl, only working with syllables. The chapter ends with several more technically allusive paragraphs which briefly consider other ways of parsing.
The book's short final chapter, Using probabilistic grammars, brings together the considerations of probabilities presented in Chapter 7 and the simple Definite Clause Grammars of Chapter 8. The chapter begins with the observation that "Human grammaticality judgements are gradient" [252]. This, and a number of other factors, lead to the elaboration of a probabilistic grammar in which each of the rules receives a probability rating and in which the sum of all sentence probabilities is 1. Probabilities will initially depend upon a reference corpus, but this will, as before, pose the problem of how to deal with sentence structures which include rules that are not attested in the corpus. Coleman considers these problems before looking at an example of such a probabilistic grammar, written in Prolog. We are shown how the grammar, which includes a very limited lexicon and set of rules, allows us for example to calculate the probabilities associated with acceptable sentences. Within this sort of grammar it is still difficult to integrate collocations such as kick the bucket or the semantic constraints which make the emaciated man starved a more likely sentence than the emaciated man was fat. One way of dealing with these difficulties is by using bigger chunks of sentence as primitives in what are called Tree adjoining grammars. In a similar vein, data oriented parsing constructs a corpus with "syntax trees instead of grammar rules" [272].
ISLP ends with a table presenting the ASCII codes, a useful fourteen-page glossary of technical terms and a full list of references.
In conclusion, ISLP is an ambitious attempt to initiate non specialists to complex techniques for speech and language processing. I found it somewhat difficult to follow occasionally but I suspect that, had I followed all the advice for complementary and preparatory reading (notably in C and Prolog programming), a good many of my difficulties would have evaporated. ISLP is, in any case, undoubtedly more suited for use as a course manual than as a self-study book. In general the explanations provided are clear and Coleman's tone always encouraging. The author has a mission to reconcile otherwise separate disciplines and writes engagingly throughout. A large amount of complementary material is generously included, both on the CD-ROM and online, to help the reader along as much as possible.4
I would recommend ISLP as an excellent starting point for the linguistics researcher who wants to know more about how computational techniques can apply to his or her discipline.
1. This and the other figures are reproduced by kind permission of the author. back
2. N. Chomsky, Syntactic Structures (The Hague: Mouton, 1957). back
3. N. Chomsky, op. cit, N. Chomsky, Aspects of the Theory of Syntax (Cambridge, MA: MIT Press, 1965) and N. Chomsky & G.A. Miller, "Finitary models of language users," in R.D. Luce, R.R. Bush & E. Galanter eds., Handbook of Mathematical Psychology, vol. II (New York: John Wiley, 1963) 419-91. back
4. One very minor caveat: the sound editor Cool Edit is shareware and is not fully functional unless paid for. The SAVE function, in particular, stops after 30 days. The freeware sound editor Audacity is able to do all that is required within the scope of ISLP. back

